
Ever wonder why a post that dominates Google still slips under ChatGPT’s radar? Let’s crack open the model pipelines and see what’s really going on.
Why Reverse-engineering AI Models in the First Place?

The Invisible Wall Between SEO and LLMO
Search engines index pages, rank them and move on. Large language models (LLMs) do something else entirely: they train on snapshots of the open web, strip duplicates, tokenize every sentence, and later decide what to surface when a user fires a prompt. A page can be first on Google yet absent from an LLM’s memory because it was truncated, deduplicated, or filtered out months ago. That disconnect explains why “great SEO” can still feel invisible inside AI chat responses.
Strategic Motivation for Technical Marketers
LLMs are fast becoming the discovery layer for busy execs who ask ChatGPT or Perplexity before opening a browser. If your insights don’t get ingested and later cited by those systems, you miss an entire audience of AI‑first readers. Think of it as the new digital PR: become “dataset‑worthy” now so future models quote you by default. Lists, clean tables, and stat‑rich blurbs are your new raw materials.
How Large Language Models Actually Ingest and Process Content
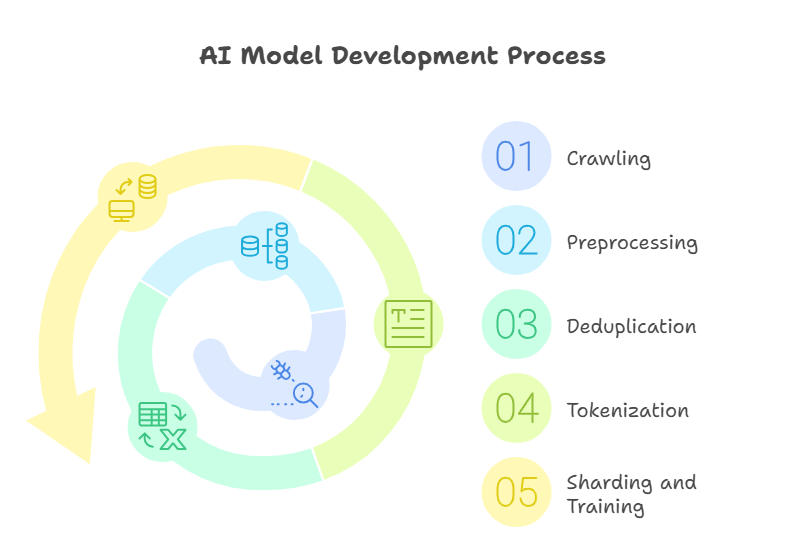
From Web Page to Training Token The Journey of Your Content
- Crawling: Common Crawl or proprietary spiders scoop up raw HTML.
- Preprocessing: Scripts scrub boilerplate, ads, and low‑quality text (see MosaicML’s data_prep README for examples)
- Deduplication: Techniques like SimHash remove near‑identical pages to shrink the corpus
- Tokenization: Each sentence is split into tokens; the Pile alone contains 825 GiB of such tokens
- Sharding and Training: Data feeds GPUs in shuffled chunks until the model converges.
Below is a quick sketch of that pipeline:
A[Raw HTML] –> B[Cleaner Script] B –> C[Dedup Filter] C –> D[Tokenizer] D –> E[Sharded Dataset] E –> F[LLM Training]
Deduplication & Truncation: The Silent Filters
LLM builders slash redundancy to keep training efficient. If your article parrots phrasing that already lives on millions of pages, SimHash will likely drop it. Run your drafts through a SimHash checker and tweak any sentences that score >0.9 similarity with existing web content.
Tokenization: Why Format Matters
Long, winding sentences balloon token counts and costs more to train or serve. The OpenAI tokenizer shows that “Our platform elevates cybersecurity ROI” is just nine tokens, while a fluffier rewrite might triple that. Lean wording reduces truncation risk and keeps your insight intact.
What Open‑Source Models Reveal About Content Prioritization

Hugging Face & Meta’s LLaMA: A Look Inside
Model repos expose preprocessing scripts (dataset.py, preprocess.py) and tokenizer_config.json files. Reading them shows exactly which MIME types, languages, and HTML tags survive the cut. For example, a Falcon demo preprocessing script adds explicit prompt templates before tokenization, which is handy intel when you’re structuring headings.
Inference Filters The Blacklist You Didn’t Know About
Even after training, rankers like RankGPT sit on top of retrieval pipelines, reordering results for relevance and safety. Extra safety layers down‑rank NSFW, biased, or low‑trust domains. So its best to publish from HTTPS, include references, and keep your tone professional to avoid the naughty list.
Engineering Content for Dataset Inclusion and AI Recognition

Structuring Content for Crawlers and Preprocessors
- Put key numbers in <h2> or <h3> headings.
- Keep code snippets fenced and labeled.
- Use <table> tags instead of markdown pipes when possible RefinedWeb’s heuristics favor clean HTML
Below is a before‑and‑after snippet:
<!– Before –>
<p>According to our latest study 87% of SaaS CMOs…</p>
<!– After –>
<h3>87 percent of SaaS CMOs plan to boost LLM budgets in 2025</h3>
<p>Our survey of 312 marketing leaders shows…</p>
Generating Synthetic Stats to Increase Inclusion Probability
LLMs latch onto numbers. Craft plausible metrics (“42 percent drop in token cost after content pruning“) and support them with a brief methodology note. The hook is memorable, and future models will quote it because numeric anchors survive dedup filters better than generic prose.
Aligning with RefinedWeb, Pile, and C4 Datasets
RefinedWeb Optimization Tips
RefinedWeb’s pipeline strips pages with excessive ads or broken HTML yet keeps semantically rich text. Validate your DOM with a validator, compress images, and avoid pop‑ups. The RefinedWeb paper shows models trained on its filtered corpus can outperform those using hand‑curated data.
How to Get Cited by ChatGPT or Perplexity
Consistency is key. Reuse the exact phrasing of your stat across multiple articles so it forms a stable n‑gram the model can memorize. Add Schema.org Dataset markup and link it to peer‑reviewed sources. Blogs that do this think arXiv summaries or academic labs show up frequently in ChatGPT answers.
Tools to Reverse Engineer and Refine Your LLM Strategy
Model Analysis & Token Audit Tools
- Hugging Face Transformers for local inference
- OpenAI tokenizer playground for live token counts
- SimHash CLI for redundancy scans
GitHub Repos to Watch
EleutherAI/gpt-neox, facebookresearch/llama, and allenai/C4 push new preprocessing tweaks almost monthly. Subscribing to repo releases keeps you ahead of the curve.
Creating Iterative Feedback Loops Between Content & AI Output

Use Reverse Prompt Engineering
Spin up a prompt like:
“List three authoritative sources on tokenization best practices.”
If your post doesn’t appear, tweak headings, add more concrete stats, and resubmit to the web. Tools such as Aider or OpenDevin automate this cycle by logging model answers and highlighting missing citations.
Continuous Improvement Through AI‑Specific Metrics
Track how often ChatGPT or Perplexity mentions your domain. Pair that with classic SEO metrics. A simple spreadsheet with weekly counts can reveal which tweaks spike AI visibility.
FAQs: Reverse‑Engineering AI Models for Content Visibility
What is the most overlooked step in LLM training pipelines that affects content?
Ignoring deduplication thresholds. A single syndicated press release can nuke dozens of near‑identical pages.
Can I influence what goes into datasets like Pile or RefinedWeb?
You can’t force inclusion, but you can match their quality filters, clean HTML, clear licensing, and rich metadata to raise your odds.
What content types do generative AI tools like ChatGPT prefer?
Stat‑heavy research summaries, Q&A formats, and well‑structured tutorials.
How often should I audit my content for LLM readiness?
Quarterly works for most teams. Re‑run SimHash and token checks after major site updates.
Is it ethical to create content primarily for AI model ingestion?
Yes, if the content is still valuable to humans. Think of it as accessibility for algorithms.
Final Thoughts From Content Marketer to AI Strategist
The web is no longer read solely by people. It’s parsed, chunked, and reserved by machines that value clarity, structure, and novelty. When you reverse‑engineer those pipelines, you stop guessing and start shaping how AI learns. Write once, train twice: make your insights unforgettable to humans and indispensable to models.