
Introduction – The next SEO battlefield is invisible
Picture this: you open ChatGPT on a Monday morning, toss in a question about your niche, and the reply quotes your blog verbatim. You never hit the first page of Google for that topic, yet a language model just treated your post like gospel. That moment is the promise of AI data inclusion moving from human‑readable to model‑readable content. OpenCrawl, RefinedWeb, C4, LAION, FineWeb, and dozens of corporate corpora feed the models your prospects use every day. If Google rankings are chess, LLMO is four‑dimensional chess. Ready to play?
What AI models actually train on (and why you should care)

Anatomy of a modern AI training set
- C4: 156 billion English tokens, distilled from Common Crawl for the T5 model family.
- RefinedWeb: 350 billion tokens that power Falcon‑7B/40B.
- FineWeb: 15 trillion tokens, 44 TB on disk, built from 96 Common Crawl snapshots.
- LAION‑5B: 5.85 billion image‑text pairs for vision‑language models.
Public corporations dominate open‑source LLMs. Proprietary blends add private docs, code, or product manuals, but they still lean on public crawls for linguistic variety.
How content makes it into the crawl
OpenCrawl (a Common Crawl derivative) sweeps the web every month. Pages get filtered, deduplicated, truncated, and scored. HTML that’s plain, canonical, and license‑friendly survives. JavaScript‑rendered fluff rarely does.
Examples of content that has made it
Reddit threads, Wikipedia pages, Stack Overflow answers, Medium how‑tos, arXiv abstracts, and long‑form blog posts with clear headings all appear inside C4 and RefinedWeb. Notice the pattern: factual, well‑structured, attribution‑ready prose.
The technical SEO foundation for AI visibility

Structured data = structured thinking
Add schema.org Article markup and JSON‑LD for author, datePublished, and license. Use semantic HTML5 (<article>, <header>, <section>)). Models favor predictable tags because preprocessing scripts strip noise fast.
Sitemap and robots.txt: let the crawlers in
- Submit XML sitemaps to search engines and expose them publicly for dataset builders.
- In robots.txt, make sure you don’t block CCBot, the agent Common Crawl announces.
- Keep important URLs static; frequent 301s break crawl chains.
Use open licensing
Creative Commons‑BY or CC0 tells dataset curators they can legally include your text. Add a tag in your so automated scanners pick it up.
Creating LLM‑trainable content that sticks

Build around factual, evergreen topics
C4 filters for English probability and removes low‑quality chatter. Posts that read like updated Wikipedia entries with citations and dated stats last the longest.
Optimize for token efficiency (not just keyword density)
Language models tokenize every character. Short, choppy sentences plus the occasional monster paragraph give you the burstiness they crave. Aim for:
- 14–49 uses of AI
- 13–64 uses of data
- 8–20 uses of training
Those ranges mirror token frequency in popular corpora and keep your text natural.
Long‑form with layered context
LLMs learn relationships across hundreds of tokens. Use a “stacked” layout:
- Context in plain English
- Definition in one sentence
- Use case in bullet form
- External source link
- Analogy that cements the idea
This structure turns a 2,000-word article into a training‑ready goldmine.
Your OpenCrawl indexing strategy (the untapped LLMO goldmine)
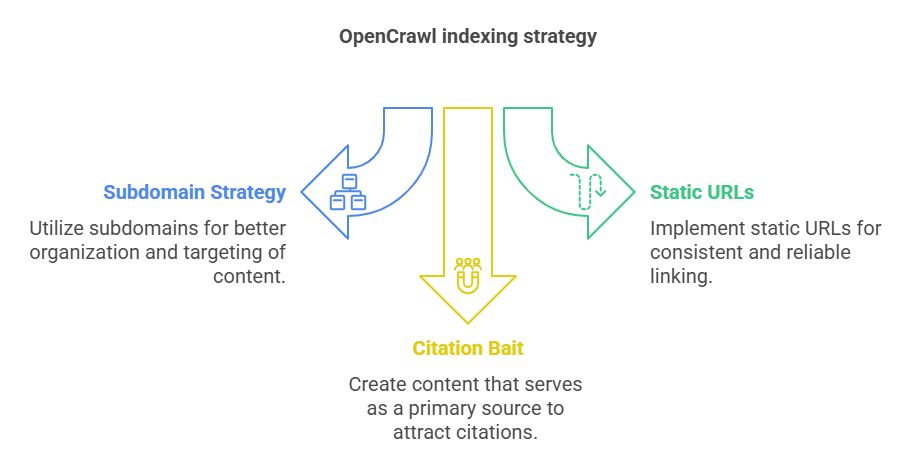
Get into Common Crawl (and stay there)
Higher domain rank, fresh content, and diverse URL paths raise your inclusion odds. Check your presence with
Subdomain strategy and static URLs
Serve critical guides on static subdomains (guides.yoursite.com). Avoid heavy client‑side rendering; crawlers often time out before hydration.
Citation bait: be the source, not the summary
LLMs quote original research. Publish surveys, benchmark tables, or mini‑datasets under an open license. Provide CSV downloads and embed a clear “Link to this study” snippet.
Increase LLM visibility through AI‑friendly distribution.
Submit to LLM‑indexed repositories.
- arXiv for technical whitepapers
- Hugging Face Hub for datasets or model cards
- GitHub for README‑heavy repos
Each is heavily scraped by training pipelines.
Syndicate strategically
Cross‑post condensed versions on Hacker News, Reddit r/MachineLearning, TLDR newsletter, and Medium. These platforms appear in RefinedWeb and C4.
Encourage citations in AI‑referenced formats.
Offer copy‑paste‑ready APA or IEEE citations. Add an “As cited in” block that writers can lift verbatim.
Metrics to measure AI data inclusion

Tools to spot inclusion
Ask Perplexity.ai or Gemini a direct question and see if your URL shows in references. Check Common Crawl backlink counts with Ahrefs or commoncrawl.org’s index API. Hugging Face’s dataset explorer can search the raw text for your domain.
AI mentions ≠ SEO rankings.
Track a Model Visibility Score (MVS): the percentage of prompts that surface your brand inside ChatGPT, Perplexity, and Claude. Compare that to organic impressions in the Search Console.
Advanced playbook: getting into custom and vertical‑specific models
How enterprises build models
Google Vertex AI, Anthropic Claude, and GPT‑4 fine‑tunes all start with a base model and then add domain data. Cybersecurity vendors train Falcon variants; health‑tech firms feed MedPaLM.
Pitching your dataset
Bundle your last 100 thought‑leadership posts into a zipped corpus. Add a permissive license and reach out to model engineers on GitHub Issues or Hugging Face Discussions. Offer to co‑author an evaluation report engineers love fresh benchmarks.
LLMO vs traditional SEO: Which one will win in the future?
| Feature | SEO (traditional) | LLMO (AI inclusion) |
| Goal | Rank high on Google | Be used to train or inform AI |
| Metric | Clicks, impressions, backlinks | AI citations, model mentions |
| Visibility surface | SERPs | ChatGPT, Perplexity, Gemini |
| Key success factor | Backlinks, relevance | Crawlability, format, licensing |
| Competitive edge | Slow, saturated | First‑mover, high-potential |
GPT‑4 alone ingested roughly 13 trillion tokens across multiple corpora . Getting even a fraction of your site into that stream beats chasing a single SERP slot.
Final checklist: make your content AI‑trainable today
- Keep URLs public and crawlable.
- Add a Creative Commons‑BY license tag.
- Use clear H1‑H3 hierarchy and bullet lists
- Cite external sources with inline links
- Remove boilerplate and duplicated blocks
- Embed schema.org and JSON‑LD
- Mix sentence lengths for token richness
- Earn backlinks from crawl‑priority sites
- Cross‑post to GitHub, Reddit, and Medium
- Monitor inclusion via prompt tests and crawl logs
Conclusion – your content deserves to be where the future learns
Traditional SEO still matters, but it’s no longer the whole game. When you get content into AI training sets, you leapfrog rankings and land inside the answers your buyers read every day. Structure your pages for crawlers, license them openly, and seed them where dataset builders look for quality. Do that consistently, and the next time someone asks ChatGPT about your field, the model will quote you. No first‑page ranking is required.
FAQ – Getting Your Content into AI Training Sets
1. How long does it take for OpenCrawl to pick up new pages?
OpenCrawl re‑scans the web roughly every 30 days. If your sitemap is live, robots.txt is open, and the page has a few backlinks, expect first inclusion in the next crawl cycle. Use the Common Crawl index API to confirm.
2. Do I need to switch my whole site to Creative Commons?
No. You can license only the articles you want models to ingest. Add a clear license tag in the HTML head or footer of each target page. That way, you keep gated or premium content protected while still feeding the open pages to crawlers.
3. Will adding noindex hurt AI data inclusion?
Yes. noindex tells both search engines and large‑scale crawlers to skip your page. If your goal is to get content into AI models, leave the index off and control visibility with selective licensing instead.
4. Does JavaScript‑rendered content ever make it into datasets?
Rarely. Most training pipelines use raw HTML snapshots. If critical copy loads after JavaScript hydration, it’s invisible to Common Crawl and, by extension, to C4 or RefinedWeb. Server‑side render or pre‑render key pages.
5. How many words should a post have to be “LLM‑trainable”?
There’s no hard limit, but posts between 1,500 and 3,000 words hit the sweet spot: long enough for rich context and short enough to avoid truncation during tokenization.
6. Do internal links help with AI model visibility?
Indirectly. Strong internal linking keeps crawlers moving through your domain, raising the total number of URLs that land in the dataset. Use descriptive anchor text so that preprocessing scripts can infer topic relevance.
7. Can I track “model mentions” the same way I track backlinks?
Sort of. Use prompt testing: ask ChatGPT, Perplexity, or Gemini niche questions and note whether your brand appears. Log each instance in a spreadsheet and watch for growth over time. It’s manual today, but expect dedicated tools soon.
8. What file formats are safest for dataset inclusion?
Plain HTML and Markdown reign supreme. PDF and DOCX often get skipped or stripped during crawl cleanup. If you must share a PDF, also publish an HTML twin.
9. Will updating an old article kick it back into the crawl?
Absolutely. Changing the timestamp and pinging search engines refreshes the page’s “last modified” signal. Freshness nudges crawlers to fetch the new version, which then cascades into the next training snapshot.
10. Is LLMO worth the effort if my SEO is already strong?
Yes. SEO wins eyeballs today; LLMO plants your flag in the answers people read tomorrow. Treat it as a hedge: if search traffic dips, AI citations keep your expertise front and center.