
Introduction
In the rapidly evolving world of artificial intelligence, access to high-quality synthetic data is crucial for building accurate and efficient models. However, real-world data often presents challenges such as privacy concerns, collecting data at scale, and inherent biases. Synthetic data generation is a method that helps organizations produce artificial data that mimics real-world data, creating privacy-safe, highly scalable, and diverse datasets for AI training and other data analytics tasks.
According to Gartner, by 2024, 60% of the data used for AI training will be artificially generated data. Many organizations, including Google, OpenAI, and Tesla, are already leveraging these data generation tools to use synthetic data that resembles real data while ensuring compliance with data privacy regulations.
This guide provides a step-by-step approach to synthetic data generation, covering the best tools, generative AI techniques, benefits of synthetic data, real-world examples, and best practices to help you create synthetic data effectively. By following these methods, you can generate synthetic data that mirrors actual data points without exposing sensitive data.
What is Synthetic Data?

Understanding Synthetic Data in AI Development
Synthetic data is artificially generated data that replicates the characteristics of real-world data without containing any actual personal or sensitive data. It uses machine learning models, generative adversarial network algorithms, large language models (LLMs), generative pre-trained transformer architectures, and statistical methods to produce structured or unstructured datasets. By leveraging these advanced data generation tools, organizations can produce synthetic datasets that resemble real data.
Key Benefits of Synthetic Data
- Improved AI Training: By generating synthetic data, organizations gain large-scale, diverse data points for machine learning model development. This helps refine patterns from the training data and reduces overfitting.
- Eliminates Bias: Synthetic data generation tools can produce synthetic data that balances demographic attributes, minimizing bias in real-world data often. It depends upon the prompt or direction we want to take.
- Cost-Effective: It reduces expenses associated with collecting data from real sources, ensuring a high level of data efficiency and enabling data analytics without needing actual data.
- Accelerated Creation: Synthetic data can be generated quickly, enabling faster iteration and data augmentation practices for test data generation and data generation for software testing.
Synthetic data is also a powerful tool for generating data that mimics real-world data, which helps accelerate innovation and model development.
Real vs. Synthetic Data: Key Differences

Below is a quick comparison that outlines the advantages of synthetic data vs. real data for AI training, machine learning, and test data generation.
| Aspect | Real Data | Synthetic Data |
| Accuracy | Based on real-world interactions but may contain errors. | Can be generated with precise control over data characteristics. |
| Bias | Inherits biases from real-world data collection. | It can be customized to reduce bias and enhance fairness. |
| Privacy Risks | Contains sensitive data that may cause compliance issues. | One can prompt it to produce Privacy-friendly by contains the data available on public sets without real personal identity information. |
| Cost | Expensive to collect and label. | Cheaper and scalable, especially for large AI training datasets. |
| Scalability | Limited by availability and accessibility of real-world data. | Can be generated on-demand, in unlimited quantities. |
How is Synthetic Data Used in AI & Cybersecurity?
Key Applications of Synthetic Data
Organizations use synthetic data to train machine learning models for various real-world tasks. This artificially generated data can be applied in numerous domains to provide a privacy-safe alternative to original data.
- Cybersecurity and Fraud Detection: Training AI models and generative algorithms to detect emerging cyber threats, malware, and fraudulent activities. By generating synthetic data that mimics suspicious patterns, cybersecurity professionals can practice advanced defense methods without risking sensitive data exposure.
- Software Testing and Development: Data generation for software testing is easier when you produce synthetic data. It creates realistic data scenarios and synthetic test data for QA teams, ensuring thorough model and code evaluation before deployment.
- Self-Driving Cars and Robotics: Generating synthetic data helps autonomous vehicle systems learn from existing data patterns and handle edge cases, significantly reducing the reliance on real data that often has limited coverage of rare driving scenarios.
- Healthcare and Medical AI: Generating artificial patient records that are in accordance with data privacy laws and can speed up research. This method enables the healthcare sector to utilize data for ML applications without endangering patient confidentiality.
- E-commerce and Marketing AI: Businesses use synthetic data to create data sets that closely resemble consumer behavior, enabling advanced recommendation systems and data analytics to optimize user experience.
- Forecasting: By combining with open-source forecasting models like Meta Prophet, businesses can get better recommendations by tweaking their biases in a cost-effective manner.
For example, Tesla trains its Autopilot AI using millions of synthetic driving simulations instead of real-world crash data.
At Mokshious, we don’t guess. We use cold, hard data; straight from Google Search Console. Clicks. Impressions. Dates. All crunched to forecast what’s actually working in your marketing… and what’s just dead weight.
Want to DIY it? Here’s a Google Colab we rigged up. Updated with all the algo changes through March 2025. No fluff. No filler.
Or skip the geek stuff and book a demo. We’ll walk you through it and show you how the pros do it.
Step-by-Step Guide to Generating Synthetic Data
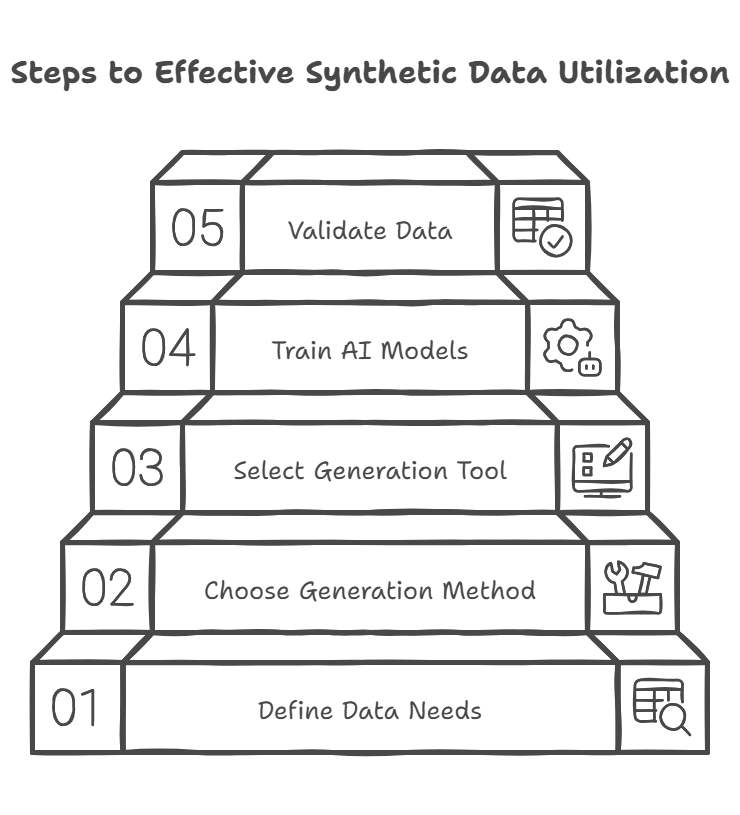
Step 1: Define Your Data Needs
- Identify the synthetic data type that you need, i.e., tabular, text, image, video, or time series. This determination is based on the AI method, machine learning model, or test data generation strategy you’re going to adopt.
- Identify the specific AI application (for example, fraud detection, cybersecurity, or healthcare) and consider whether you need to create synthetic data that aligns with existing data.
- Gauge the complexity of features, relationships, and data points to ensure the synthetic dataset accurately represents real data patterns and baises.
Example: If you’re building an AI fraud detection system, you will need synthetic transaction data with variables like transaction amount, time, location, and merchant type.
Step 2: Choose the Right Synthetic Data Generation Method
Different algorithms and generative AI methods are used to generate synthetic data. Below are popular approaches often implemented by synthetic data generation tools.
| Technique | Best For | Pros | Cons |
| Generative Adversarial Networks (GANs) | Image & Video Data | High-quality, realistic data | Requires large computational power |
| Variational Autoencoders (VAEs) | Text & Anomaly Detection | Good for generating structured data | May struggle with highly complex patterns |
| Large Language Models (LLMs) | Text Generation | Creates highly coherent text data | It may generate biased outputs if not fine-tuned |
| Monte Carlo Simulations | Finance & Risk Analysis | Models real-world randomness | Computationally expensive |
| Rule-Based Simulation | Business Process Automation | Easy to implement | Limited variability |
Step 3: Select a Synthetic Data Generation Tool
Once you have identified your desired approach, select a synthetic data generation tool that aligns with your needs. These platforms can vary in focus, whether you need tabular data for financial models, textual data for LLM-based solutions, or synthetic test data for software testing. Below are some of the top synthetic data generation tools.
| Tool | Best For | Pricing | No-Code Support |
| MOSTLY AI | Tabular Data | Paid | ✅ Yes |
| Gretel.ai | Text & Image Data | Paid | ✅ Yes |
| AI.Reverie | Autonomous Systems | Enterprise | ❌ No |
| Hazy | Privacy-first AI | Paid | ✅ Yes |
Each tool has unique features, including data privacy controls, scalability, and integration options.
Step 4: Train AI Models on Synthetic Data
After you produce synthetic data, the next step is to train your AI model. Here are some guidelines:
- Ensure diversity: Prevent the creation of overly homogeneous synthetic datasets. Diversify data points so that machine learning models are able to learn a wide variety of patterns from the training data.
- Test for bias: Compare distributions of synthetic data and original data to detect potential biases. This is crucial for fairness and compliance with data privacy regulations.
- Fine-tune models: Adjust hyperparameters and perform practice runs to optimize AI performance. If the algorithm or method used for data generation was a generative adversarial network (GAN) or large language model (LLM), fine-tuning can improve the final results.
Example: Synthetic data is applied by Google in training AI-fueled speech recognition technology to better comprehend multitudinous accents and languages
Step 5: Validate and Compare Synthetic vs. Real Data
Comparing synthetic data to real data is crucial before deploying any machine learning model:
- Distribution Similarity: Evaluate how closely the synthetic dataset resembles the original data distribution by calculating metrics like KL Divergence or Wasserstein Distance.
- Performance Metrics: Train your algorithm on real vs. synthetic data for ML tasks, then compare F1-score, precision, and recall. This reveals whether the artificially generated data meets the required level of data quality.
- Bias and Fairness Testing: Confirm the produced synthetic data does not replicate discriminatory patterns from existing data.
- Real-World Testing: Conduct test data generation to ensure the model performs well in real scenarios.
Example: A cybersecurity firm generates synthetic phishing email datasets to practice advanced spam filtering while protecting sensitive data and complying with data privacy regulations.
Best Practices for High-Quality Synthetic Data

To ensure synthetic data maintains high quality, remains accurate, respects data privacy, and provides genuine benefits of synthetic data for machine learning, organizations should follow these best practices in the creation and use of artificially generated data. Below are the critical steps.
1. Ensuring Accuracy and Diversity
Synthetic data must be realistic and diverse to be effective for AI, cybersecurity, and data analytics. Here is how to create synthetic data that achieves the best results:
- Avoid overfitting to synthetic patterns: Ensure the machine learning model trained on synthetic data can generalize to actual data by introducing variability.
- Maintain statistical similarity to real data: Use generative adversarial network algorithms or variational autoencoders to produce synthetic data that mimics real-world distributions.
- Balance data attributes: For fraud detection or cybersecurity scenarios, incorporate a range of normal and malicious behaviors in the synthetic dataset.
- Combine multiple generation methods: Combining generative AI methods with rule-based simulations can improve data augmentation and diversity.
- Validate against real benchmarks: Compare synthetic data points with original data sets to confirm that the synthetic dataset closely resembles real data.
Example: A company developing AI-powered cybersecurity threat detection should generate diverse synthetic cyberattack logs to avoid bias toward specific attack patterns.
2. Data Privacy and Compliance Considerations
Although synthetic data does not include real personal data, privacy risks may still arise if the data generation process inadvertently reflects original data too closely. To maintain compliance with data privacy regulations such as GDPR, CCPA, or HIPAA, follow these guidelines:
- Use differential privacy: Use privacy-safe methods such that synthetic data can be produced without revealing sensitive information from the original dataset.
- Conduct frequent audits: Inspect your method or algorithm to detect potential data leakage.
- Choose privacy-first platforms: Many synthetic data generation tools offer built-in compliance with data privacy regulations to ensure you produce synthetic data ethically.
- Ensure legal and ethical use: Document your data generation for software testing or other scenarios to demonstrate compliance with data governance rules.
- Maintain transparency: If you use synthetic data in public-facing AI models, clarify how the artificially generated data was created and validated.
Example: A healthcare AI company using synthetic patient data for medical research must ensure that no real patient records can be inferred from the synthetic dataset.
3. Choosing the Right Synthetic Data Generation Tools
When choosing a data platform to create synthetic data, look at the data type, privacy needs, and integration simplicity:
- Match the platform to your data type: Some synthetic data generation tools focus on tabular data, while others excel at producing images or text-based data.
- Assess no-code vs. code-based solutions: A no-code platform can help teams without a strong technical background create synthetic data quickly.
- Verify privacy features: Ensure the tool includes differential privacy and bias mitigation.
- Test with sample datasets: Start with small-scale tests to confirm the synthetic data meets your organization’s requirements before going into full-scale test data generation.
Example: A financial services firm training an AI fraud detection model should use MOSTLY AI to generate realistic but privacy-safe transaction datasets.
4. Validating the Quality of Synthetic Data
Use these steps to validate the quality of your synthetic data:
- Similarity metrics: Calculate KL Divergence or Wasserstein Distance to compare distributions between real and synthetic data.
- Model performance assessment: Train your machine learning model on real and artificially generated data to measure differences in accuracy, precision, and recall.
- Data leakage checks: Ensure the synthetic dataset does not inadvertently include sensitive data points from the original data.
- Adversarial testing: Expose the model to extreme scenarios and edge cases to confirm its robustness under varied conditions.
Example: A self-driving car AI company could validate synthetic training data by testing its AI models on real-world and synthetic road scenarios.
5. Ensuring Long-Term Scalability and Adaptability
Effective synthetic data generation should evolve as your organization and machine learning need to grow:
- Automate synthetic data pipelines: Integrate data generation tools into your CI/CD workflows for continuous training data updates.
- Adapt to new business requirements: If your model or method changes, generate new synthetic data that aligns with updated features or real-world conditions.
- Monitor data drift: If performance declines or your original data distribution changes, regenerate the synthetic dataset to maintain accuracy.
Example: A cybersecurity firm training AI-based intrusion detection systems must regularly update its synthetic datasets to reflect new hacking techniques and malware patterns.
Future of Synthetic Data in AI and Cybersecurity

As generative AI models continue to advance, synthetic data generation will enable even more realistic data and robust machine learning model training. By 2028, experts predict that 80% of data used by AIs will be synthetic. This trend is especially relevant in cybersecurity, where advanced threat simulations rely on test data generation to stay ahead of cybercriminals.
Example: MIT researchers are developing AI-driven synthetic data platforms to create realistic attack simulations for cyber defense training.
Conclusion
Good quality synthetic data is a very potent weapon in the development of AI, providing privacy protection, scalability, and better model accuracy. However, it requires diversity, accuracy, privacy conformity, validation, and scalability to ensure its highest utility.
By following best practices and leveraging advanced synthetic data generation tools, businesses can generate synthetic data that mirrors real-world data often, enhance AI model performance, and stay ahead in cybersecurity, healthcare, finance, and beyond.
FAQ: Synthetic Data Generation for Cybersecurity Businesses
1. What are generative models, and how do they support synthetic data generation?
Generative models are advanced machine learning frameworks used by data scientists to generate artificial data. They learn from real datasets and then create data that closely mimics original distributions. It produces good quality synthetic data that closely replicates real data, and that is particularly valuable for use in cybersecurity where privacy and accuracy are both paramount.
2. How can high-quality synthetic data help a cybersecurity firm stand out?
High-quality synthetic data is particularly useful for testing intrusion detection systems, training risk analysis models, and showcasing real-world threat scenarios without exposing sensitive information. Since real data often contains private or proprietary details, synthetic data can be used to provide practical demonstrations of how your services handle threats, fostering trust with potential clients and eliminating compliance hurdles.
3. What is the role of synthetic data generation algorithms in data science for cybersecurity?
Synthetic data generation algorithms form the backbone of many data science initiatives in cybersecurity. By combining these algorithms with a robust data generator, a company can quickly produce realistic, scenario-specific data for threat modeling and incident simulation. This enables cybersecurity teams to create more effective defense mechanisms and improves the overall dependability of machine learning models that are trained on synthetic as opposed to real data.
4. How can a data scientist incorporate data based on synthetic inputs into existing cybersecurity workflows?
A data scientist can integrate synthetic data into security analytics pipelines by transmitting data via secure channels, ensuring both privacy and compliance. Because the data is artificially generated, it can be refreshed frequently to keep pace with evolving cyber threats. This approach enables continuous validation, testing, and updating of security models without relying on sensitive, real-world information.