
Why “occultation” is the perfect metaphor for AI context window management

Think back to an eclipse. You’re watching the sky, and then, slowly, one body drifts across another. The glow you were depending on doesn’t fade because it’s gone; it fades because it’s been blocked from view. The hidden star hasn’t stopped shining; it’s just been blocked from view. That same phenomenon happens in large language models.
Information doesn’t always vanish; it gets buried, overshadowed, or obscured by newer tokens as the context window fills.
When we talk about context decay in LLMs, this is exactly what we mean.
Models don’t literally “forget” in the way humans do. Instead, as the input context length increases, the probability of recalling something placed earlier in the sequence starts to degrade. By the time you’re halfway through a long-context prompt, the middle can slip into darkness. This is the “lost in the middle” effect researchers keep finding in long-context benchmarks, whether the window is 8k, 128k, or even beyond.
Occultation is a sharper metaphor than simple “forgetting,” because it captures the idea of hiding without deletion. Just as a planet hides a star, a flood of new tokens can hide important details. The information is still there, embedded in the sequence, but its weight in the model’s attention mechanism is so low that it may as well be invisible. This is why context window management matters: where you place facts in a prompt, and how you compress or reorder them, can decide whether the model shines light on them or lets them vanish.
The same logic applies outside of AI. In marketing teams are created at a breakneck pace. New blogs, new campaigns, new positioning documents, and content velocity is higher than ever. That flood of information creates content shock. Just like in an LLM, the older material hasn’t disappeared. It’s still indexed, still online, still technically accessible. But in practice, it’s hidden under layers of newer updates, trending topics, and search results. Your canonical truth, pricing details, core values, and brand promises can be buried the same way a star gets eclipsed.
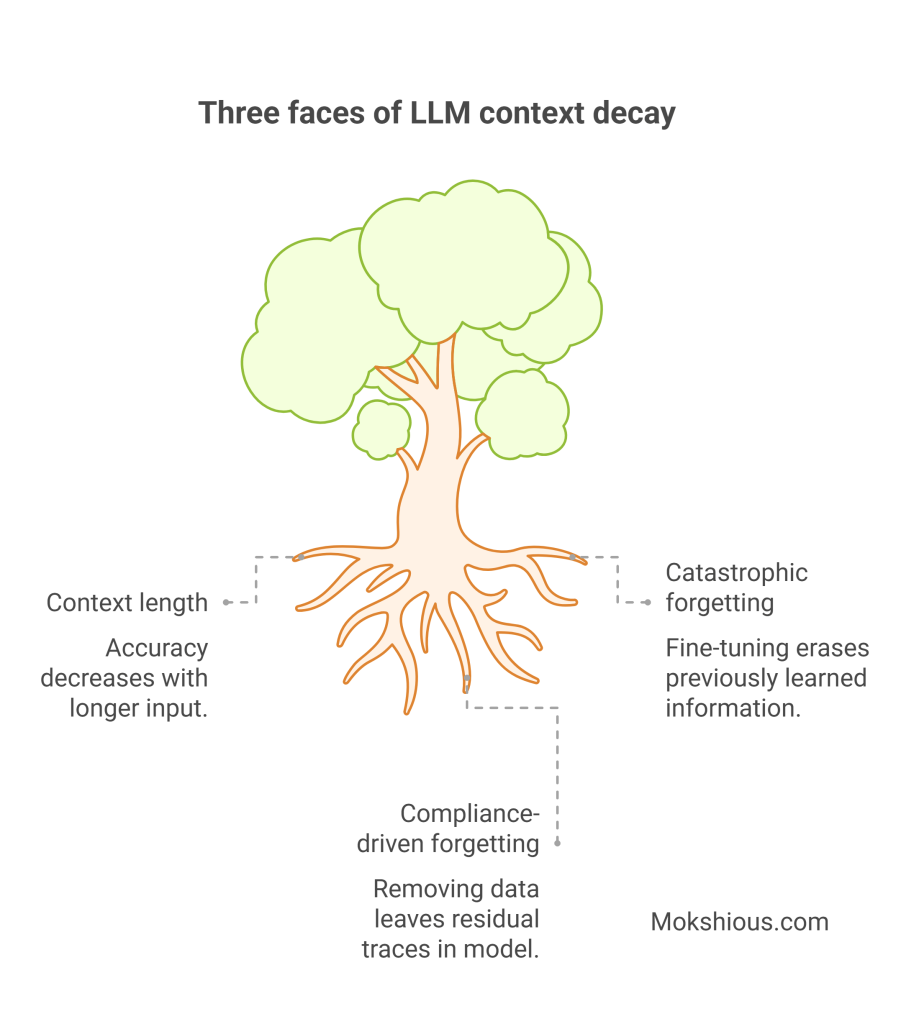
Three faces of LLM context decay (and their business parallels)
Long-context LLMs and inference-time decay: the “lost in the middle” limitation
When long-context LLMs process a giant prompt, accuracy often dips in the middle. This is the “lost in the middle” effect, and researchers show that as sequence length or input context length increases, performance decay follows. Context window size and sliding window attention only go so far; across context lengths, models still lose track.
- Example: In tests across 18 LLMs, key facts at position B/M/E showed steep drop-offs as context length increased.
- Business parallel: A long marketing deck where the long input buries your brand pillars in the middle.
Mokshious Strategy for context: Reorder prompts so vital tokens sit at the start or end, compress with context compression, or chunk sequences. That’s how you handle long contexts better.
Catastrophic forgetting in model training: when memory fades across updates
Catastrophic forgetting is when continual fine-tuning overwrites what models once knew. Every new adapter risks erasing older truths. Training context length can also skew outcomes if you keep stacking updates.
- Example: dataset amnesia when tuning on niche customer data.
- Business parallel: Every new campaign update pushes older brand memory consistency into the background.
How does Mokshious Mitigate: Using parameter-efficient tuning, test across old vs. new benchmarks, and keep a rollback model to preserve model performance.
Compliance-driven forgetting: machine unlearning
Legal frameworks like GDPR require the right to be forgotten. That means machine unlearning: cutting specific training samples while proving deletion.
- Issue: Even after removal, traces can persist in large language models.
- Business parallel: You retire old ads, but cached pages still show expired prices.
Mokshious Action: keep sensitive data in non-parametric retrieval memory so deletion is just metadata, not full retraining. Add governance & AI risk checks to your pipeline.
The LLMO optimization balance: generate, remember, occlude
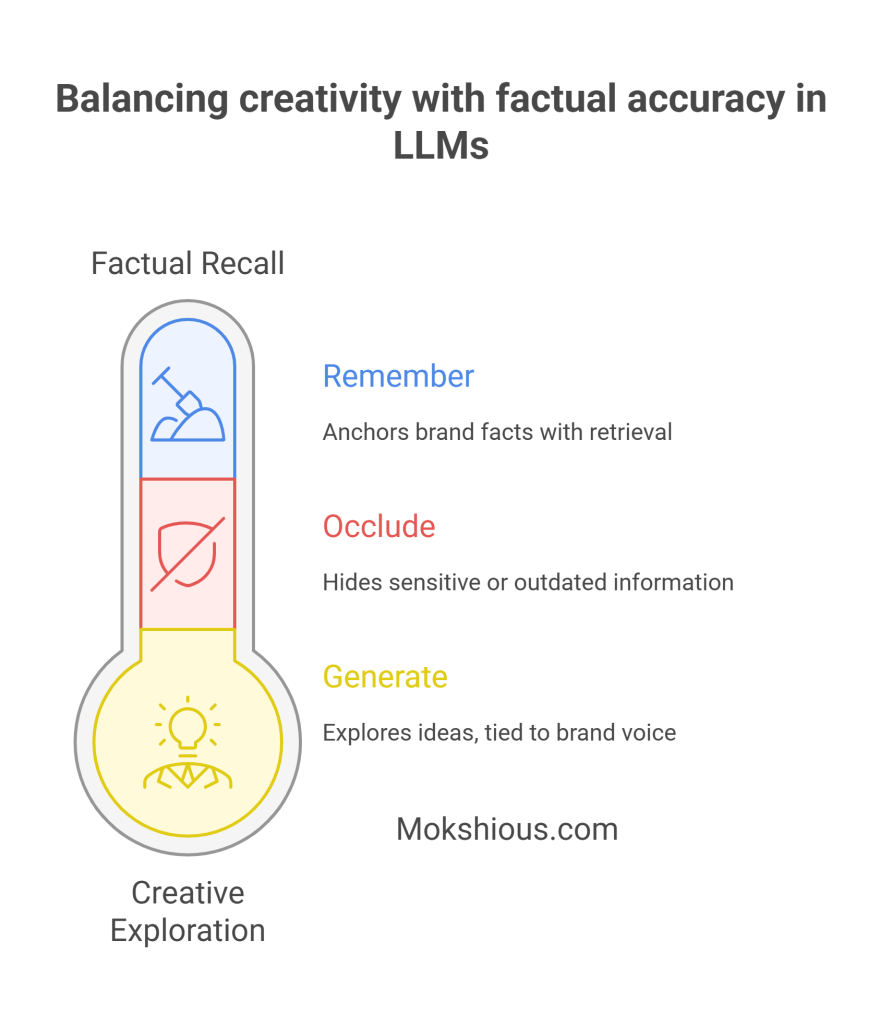
When teams talk about LLMO (large language model optimization), the conversation often drifts straight into prompts, tokens, or benchmarks. But at the heart of it, LLMO is really about balance. A model has to do three things at once: generate new content, remember what must stay consistent, and occlude what must be hidden or down-weighted. Miss any of these and you’ll feel it, either in broken brand trust, compliance headaches, or an avalanche of noisy outputs nobody wants to read.
Generate: creative content and prompt exploration without drift
Generation is the part people get excited about. It’s the magic of fresh copy, catchy headlines, or clever campaign hooks appearing in seconds. But without guardrails, that same creativity can spiral. Models tuned too aggressively for novelty might invent features your product doesn’t have or promise discounts that expired months ago.
In practice, generate means:
- Giving the model space to explore ideas, but tying it back to brand voice guardrails.
- Using prompt templates that encourage style variation without losing the thread of canonical truth.
- Embracing creative destruction in a controlled way, letting new campaigns shine without erasing the old ones.
Think of this as your “go-wide” setting: you want bold ideas, but with a tether strong enough to keep them aligned.
Remember: Anchor brand facts with retrieval-augmented memory (RAG)
If generation is the wide lens, remembering is the anchor. Every LLM deployment needs a stable layer of facts that don’t bend to creativity: pricing tiers, compliance language, product specs, and brand pillars. This is where context engineering and retrieval-augmented generation (RAG) come into play.
Practical steps include:
- Keeping a brand fact registry indexed and version-controlled, so the model has a reliable source.
- Running retrieval hit-rate dashboards to check how often the model pulls truth instead of hallucination.
- Structuring context windows so these non-negotiables sit at the front or back, not lost in the middle.
This is your “stay-true” setting: the core memory that holds even when campaigns, datasets, or teams change.
Occlude: strategic hiding for compliance and context rot management
The third dial is the least glamorous but often the most critical. Not every piece of information should surface. Occlude means deliberately hiding or suppressing items that can’t or shouldn’t appear: sensitive customer data, stale offers, deprecated features, or anything flagged by compliance.
Why this matters:
- Compliance-driven forgetting is not optional. Regulations like GDPR enforce the right to be forgotten, which means having a real unlearning or deletion route.
- Dataset amnesia isn’t accidental; it’s designed. Sometimes you want the model to down-weight outdated knowledge to avoid brand drift.
- Marketing parallels: just because last year’s campaign exists in archives doesn’t mean you want it resurfacing in every search or chatbot interaction.
The practical move here is setting up policy filters and machine learning pipelines. This is the “shadow dial”: deciding what stays in light and what gets eclipsed.
RAG-first architecture pattern for long-context LLMs
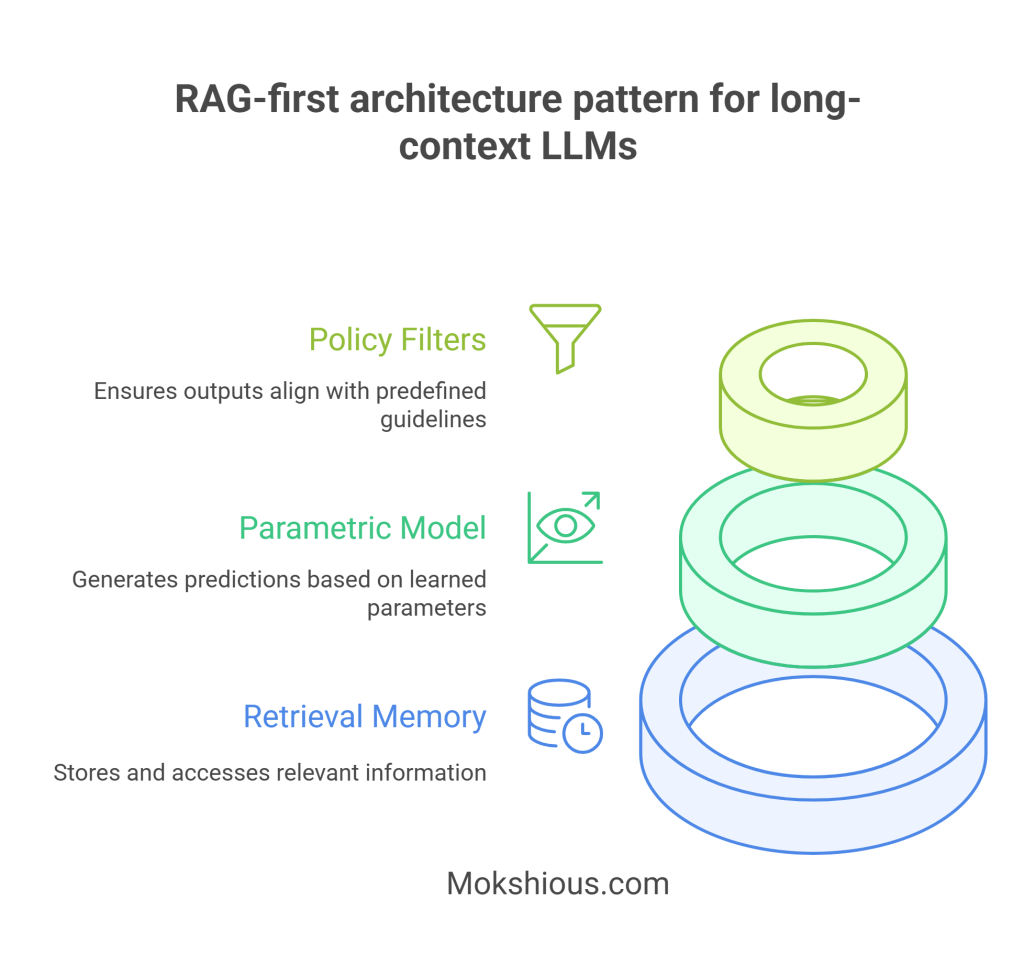
Layer 1: Retrieval memory
Use retrieval-augmented generation as a non-parametric source of truth. This architecture grounds answers in indexed docs, adds provenance, and avoids relying only on massive context windows.
Checklist for context management:
- Retrieval hit-rate ≥80% for brand facts.
- Track freshness, half-life, and long-context benchmarks.
- Audit for hallucination drift across context window management.
Layer 2: Parametric model
Keep the base model tuned for reasoning over long inputs and tone. Use adapters, not heavy fine-tunes, to reduce the risk of catastrophic forgetting. Avoid “all-in” updates that could degrade across benchmarks.
Layer 3: Policy filters
Add entitlement checks and redactions. Automate unlearn workflows for deletion. Guardrails and model spec design here protect compliance. This is governance in practice, not just theory.
The 3×A playbook for context memory risk

Every modern LLM stack has the same three risks lurking in the background: context decay, catastrophic forgetting, and compliance-driven unlearning. Left unmanaged, they chip away at trust, accuracy, and compliance. The good news is you don’t need a hundred different frameworks to keep them in check. You need one simple loop: Accrete, Audit, Attenuate. Think of it as the 3×A playbook, a repeatable cycle to grow memory, test it, and prune it.
Accrete: grow with intention
Accretion is about adding knowledge in a structured way instead of dumping random data into the model. Just like planets form by accumulating mass, your AI stack builds reliability when each new fact, doc, or policy is added with governance in mind.
Mokshious Suggested Steps:
- Add new facts into retrieval indexes with metadata: source, owner, timestamp, and version number.
- Use context engineering to chunk and tag so retrieval stays sharp even when the context window size expands.
- Require a short “claim file” for each entry, what it is, who owns it, and when it expires.
Marketing parallel: when a brand launches a new product feature, it’s not just about the launch blog. You need to accrete that knowledge into your brand memory system so campaigns, ads, and sales decks all stay aligned.
Audit: test like decay is inevitable
If you never test for drift, you won’t notice it until customers do. Audit is the checkpoint where you measure how well the system handles long sequences, how often retrieval hits, and how much performance degrades as input length increases.
Mokshious Suggested Steps:
- Run “lost in the middle” tests: Move key facts to different positions in the prompt (beginning, middle, end) and measure accuracy.
- Track retrieval hit-rate for canonical truths. If it dips below 80%, you’re flying blind.
- Keep a long-context benchmark suite and rerun it whenever you fine-tune or update your index.
- Check hallucination percentage across context lengths to catch context rot early.
Marketing parallel: Think of this like brand audits. If your new content is drowning out old core messaging, you run a campaign audit to rebalance. AI memory deserves the same oversight.
Attenuate: prune and protect
Not all memory should be eternal. Attenuation is about reducing the weight of stale, irrelevant, or risky data before it poisons outputs. It’s also where machine unlearning in generative AI and compliance-driven forgetting live.
Mokshious Suggested Steps:
- Build a “forgetting pipeline” where stale docs automatically down-rank after a freshness half-life.
- Route sensitive customer info to deletion queues with verification logs.
- Maintain governance & AI risk dashboards that track unlearning turnaround time and deletion SLA compliance.
- Down-weight outdated campaigns to avoid marketing content decay in chatbots or search.
Marketing parallel: think of attenuating as the “spring cleaning” of your content strategy. You don’t want last year’s expired discounts resurfacing in a chatbot, and you don’t want deprecated claims confusing customers.
Marketing metaphors that explain AI context limitations

Technical terms like context decay, machine unlearning, or long-context limitations can sound abstract to non-engineers. But if you translate them into marketing language, the risks and fixes suddenly click. These metaphors bridge the gap between AI labs and boardroom strategy.
Creative destruction: Model updates
In economics, creative destruction describes how innovation wipes out old industries. The same thing happens inside large language models. Each fine-tune, each new adapter, is like a startup disrupting an incumbent. The old weight patterns get eclipsed by the new ones. That’s powerful; it fuels fresh reasoning and new abilities. But it’s risky too. Overdo it and you trigger catastrophic forgetting where yesterday’s truths disappear.
For marketers, this feels familiar. Launch a bold new campaign, and it may overshadow your core message. The fix is planning migrations with the same care you’d use in product launches. Map which truths must survive, and which ones you’re willing to let go. That’s context engineering for brand safety.
Content shock: Brand memory drift
Mark Schaefer coined “content shock” to describe the flood of digital material that overwhelms audiences. LLMs have the same problem at inference. As the context window size grows, models juggle more tokens, but critical details can sink into the middle. This creates context rot; facts are technically in the input but functionally ignored.
For brands, the parallel is simple: publish too much, too fast, and your canonical story gets buried. A new blog on a niche feature hides the broader value prop. A product update post buries your pricing clarity. That’s brand memory drift. The cure is using retrieval-augmented generation (RAG) as your brand memory layer, surfacing the essentials no matter how much new content piles on.
Occultation: deliberate hiding
Occultation, borrowed from astronomy, is when one object hides another from view. In AI, this metaphor is sharper than “forgetting.” Generative Amnesiac Occultation, coined by Mokshious describes how in AI some information is still there in the sequence but has been effectively obscured. In marketing, occultation is exactly what you do with expired promotions, deprecated features, or sensitive customer data.
You don’t delete them from history; you design them to be hidden. That’s compliance-driven forgetting, the right to be forgotten in action. You decide which claims must be suppressed so they don’t resurface in outputs or search results. It’s not amnesia; it’s intentional occlusion with guardrails and model spec.
Mokshious Implementation checklist for long-context LLM context management
- Run long-context evals on 8k context, 128k context, and everything in between.
- Log token hit-rates, hallucination percentages, and reasoning accuracy across long sequences.
- Track context rot regression scores.
- Keep a brand fact registry tied to retrieval.
- Document deletion SLAs and proof logs.
- Split clearly between parametric and non-parametric knowledge sources.
FAQ
Do I need RAG with giant context windows?
Yes. Larger context windows like 128k or 1M don’t fix context decay in the middle. You still need provenance, governance, and cost control.
Will unlearning break accuracy?
It can. That’s why you should keep sensitive knowledge in non-parametric stores and use scoped adapters.
Why does LLM performance degrade with longer inputs?
Because tokens in the middle lose weight. That’s why you need context compression, chunking, and position-aware strategies.
Conclusion: Occultation must be designed, not denied
Context decay is predictable, catastrophic forgetting is preventable, and machine unlearning is unavoidable. If you design with context window management, retrieval grounding, and governance logs, you build a system that generates new ideas, remembers brand facts, and hides what must stay hidden.
The future of large language models isn’t about avoiding decay but controlling it. With LLMO optimization, you can turn context management into a growth advantage instead of a compliance risk. When you manage the balance between generation, memory, and occultation, your system keeps its edge while your marketing stays consistent, discoverable, and trusted.