
Introduction: Why Your Best Content Isn’t Making It Into LLMs
You spent months polishing that cornerstone guide. Google loves it, and readers share it, yet ChatGPT acts like it never existed. What gives? Behind every large language model sits a brutal data-cleaning pipeline. It strips away spam, boilerplate, duplication, and anything that looks off‑kilter before a single token reaches the GPUs. In RefinedWeb, for example, half the crawl vanished just for being non‑English, another 24 percent of what was left failed quality checks, and 12 percent more died as duplicates. Your page can be collateral damage unless you speak the pipeline’s language.
This guide unpacks the hidden rules, shows you how to spot red flags, and lays out a workflow that keeps your content in the data models actually read.
Understanding LLM Dataset Cleaning and Why It Matters
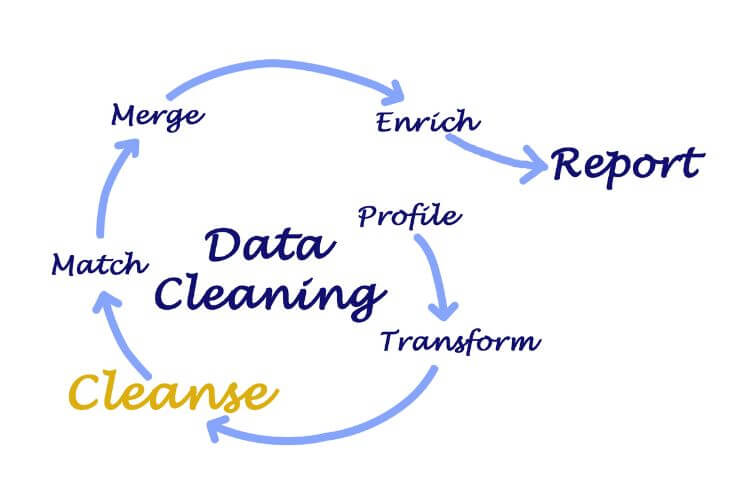
What is Data Cleaning for Large Language Models
Data cleaning for LLMs is the gatekeeping process that decides which web pages survive into training datasets like C4, Pile, or RefinedWeb. The goal is simple: feed models clean data that boost accuracy and reduces bias. Anything noisy, duplicated, or structurally weird gets tossed to protect model quality and compute budgets.
How Content Gets Excluded from LLM Datasets
- Duplication: Dedup scripts compare shingles or hashes. The Pile lost roughly a third of its size after EleutherAI’s Pythia dedup run.
- Spamminess: Language‑model‑based classifiers down‑rank pages full of keyword stuffing, click‑bait headings, or endless boilerplate.
- Poor structure: Pages without clear HTML hierarchy, missing headings, or jammed with ads often look like low‑quality noise.
- Toxic or policy‑violating text: C4 experiments show that toxicity filters can shrink a corpus to as little as 22 percent of its original size.
Real‑life shocker: a top‑ranking tutorial page was kicked out because the sidebar’s repeated nav links tripped duplication thresholds. The lesson? SEO polish alone is not enough.
Common Data Cleaning Techniques Used in AI Pretraining Pipelines

RefinedWeb Filtering Process Explained
- Language ID: Non‑English pages: gone (≈50 percent drop).
- Quality Classifier: Pages scored below a learned threshold (‑24 percent).
- Deduplication: MinHash and exact‑substring passes remove near and full duplicates (12 percent).
- Length & Charset Checks: Very short, very long, or binary‑heavy docs are nixed.
Common Crawl Content Filtering Techniques
- Shingle hashing to find clusters of similar text.
- URL pattern rules to block obvious spam domains.
- Profanity and PII filters using regex and ML classifiers.
AI Dataset Cleaning Rules for Web Content
Across C4, FineWeb, and RefinedWeb, the recurring rules are:
- Consistent language and encoding
- Logical HTML headings
- Minimal template repetition
- Low ad‑to‑content ratio
- Absence of scraped comments or nav junk
FineWeb distilled 96 Common Crawl snapshots into a 15‑trillion‑token corpus by enforcing those rules.
Technical Deep Dive: Diagnosing Your Content

Identifying Red Flags in Your Web Content
Spotting red flags in your web content is crucial for maintaining credibility and trust. Look out for outdated statistics, broken links, inconsistent tone, or overly promotional language that can turn readers away. Poor readability, lack of clear structure, and missing SEO elements are also signs your content needs attention. Addressing these issues ensures your website stays authoritative, user-friendly, and aligned with your brand goals.
Tools and Techniques to Audit Your Content
| Task | Tool | Quick Command |
| Detect near duplicates | simhash | simhash -f urls.txt -o dupes.csv |
| Check spam score | llama‑cpp + custom classifier | python spam_score.py page.html |
| Extract clean main text | readability-lxml | python extract.py page.html |
| Embedding similarity | OpenAI embeddings | Compare cosine distance across URLs |
Example snippet using Python and MinHash to flag duplicates:
from datasketch import MinHash, MinHashLSH
# Suppose you have a function that generates shingles
def shingles(text, k=5):
return [text[i:i+k] for i in range(len(text) - k + 1)]
# Create LSH index
index = MinHashLSH(threshold=0.8, num_perm=128)
# Process a document
page_text = "example document text"
mh = MinHash(num_perm=128)
for shingle in shingles(page_text):
mh.update(shingle.encode('utf8'))
# Insert into index
index.insert("/my-url", mh)Optimizing Your Content for AI Dataset Inclusion

Best Practices for Data Cleaning and Content Standardization
- Strip boilerplate with DOM parsers.
- Keep paragraphs under 120 words to avoid run‑on detection.
- Use semantic HTML: <article>, <section>, <h2> not <div class=”whatever”>.
- Provide canonical URLs and consistent metadata.
- Validate UTF‑8 and remove odd control characters.
Before‑and‑after example: Before: 6,300 words, 42 percent duplicate sidebar text, mixed encodings. After: 3,900 words, 0.5 percent duplication, validated UTF‑8, passes quality classifier.
How to Avoid Content Duplication in AI Training
- Generate unique intros and summaries per page.
- Consolidate tag pages into canonical resources.
- Use semantic rewrites rather than template copy.
- Map old URLs to new ones with 301 redirects to cut crawl overlap.
Advanced Strategies: Making Content Irresistible to LLMs
Contextual and Semantic Optimization
- Embed glossary definitions inline so models capture term relationships.
- Add structured data (FAQPage, HowTo) to supply machine‑readable chunks.
- Sprinkle diverse examples and edge cases dedup filters love variety.
Automating Data Cleaning Workflow
Set up a Python pipeline:
- Fetch sitemap daily.
- Run readability extraction.
- Deduplicate with MinHash.
- Score with a small Roberta quality model.
- Push clean HTML to a public S3 bucket for crawler pickup.
A Spark job on Common Crawl logs can flag mentions of your domain, showing if the cleaned pages propagate.
Benchmarking and Measuring Success
Establishing Data Quality Benchmarks
| Metric | Good Threshold |
| Duplicate token rate | <1 percent |
| Boilerplate ratio | <20 percent |
| Quality classifier score | >0.8 |
| Language confidence | >99 percent |
Monitoring Inclusion in Training Pipelines
- Search RefinedWeb or mC4 index dumps for your domain.
- Use BigQuery’s public Common Crawl table to track snapshot frequency.
- Watch for model citations in tools like Perplexity’s sources pane.
Common Mistakes and How to Avoid Them

- Over‑templating: Sidebars repeated on thousands of pages look like spam.
- Ignoring encodings: Hidden Windows‑1252 characters can tank language ID.
- Mass content sprawl: Thin tag pages add duplicate noise.
- Leaving UTM clutter: Tracking params create URL duplicates.
- Neglecting alt text: Missing descriptions flag low‑quality HTML.
Fixing these bumps affects quality scores and reduces crawl loss.
FAQ: Quick Answers
Why do AI models ignore certain websites?
They inherit the filters above; if your pages look like spam, duplicates, or low‑signal boilerplate, they never reach training.
How does spam filtering in AI pretraining work?
Classifiers score each document. Anything below a threshold, often 0.3 on a 0‑1 scale, is out.
What content structures improve LLM visibility?
Clear headings, descriptive alt text, and balanced paragraph lengths help language ID and quality scoring.
Can legacy content be refactored?
Yes. Run it through readability extraction, rewrite duplicate sections, and re‑publish under a canonical URL.
Is content duplication always harmful?
Some repetition is fine, but high overlap across pages can push you below inclusion thresholds.
Conclusion: Future‑Proof Your Content for LLM Visibility
Data cleaning for LLMs is ruthless but predictable. By structuring pages cleanly, eliminating duplicates, and automating audits, you raise the odds that your content survives every filter and lands inside the next generation of models. Start cleaning today so future AI actually remembers you. If you want help, feel free to contact us.