
The Token Budget Crisis
Let’s get real, context window inflation is silently crushing AI budgets. Stateful AI systems that rely too heavily on brute-force context stuffing are bleeding money with every call. Recent industry data shows that LLM usage now accounts for over 18% of cloud infra budgets in AI-driven environments. Not compute. Not storage, but the ability to maintain state in AI applications. Just context-hungry prompts.
Most stateless agents rely on massive context windows, often exceeding 100k tokens. This stateless sprawl leads to rising costs, unpredictable latency, and engineering friction. Engineers keep stacking memory into the context instead of managing the state properly, and the result is sticker shock.
Why ‘Just Increase Context Window’ Is a Financial Trap
More tokens don’t equal better performance. Expanding the context window introduces hidden architectural burdens:
- Increased latency from token scan time can affect stateful and stateless systems.
- Steeper pricing in
- LLM APIs (GPT-4o, Claude 3, etc.) can impact the deployment of stateful AI applications.
- Redundant or irrelevant memory bloating each call can hinder stateful vs stateless performance.
Even worse, performance gains plateau after 8K tokens for most use cases. The rest is just budget bleed.
Memory Models Primer (Exec Version)

Building stateful AI agents means choosing the right memory model. Not all memory is created equal, especially when considering persistent memory in stateful AI applications.
Episodic vs. Working vs. Long-Term Memory
- Episodic memory: lightweight, per-session memory, ideal for contextual continuity.
- Working memory: real-time scratchpad, great for reactive workflows.
- Long-term memory: persistent, cross-session recall requires cost-sensitive governance.
Stateful agents must manage memory across workflows and agentic steps. Use the wrong memory model and you’ll either burn tokens or forget what matters.
Summarization Windows vs. Vector Recall
Two dominant memory strategies for AI agents:
- Summarization windows: reduce token load through lossy compression; great for budget-sensitive workflows
- RAG memory (Vector Recall): semantically accurate but costly and latency-sensitive
For modern agentic systems, a hybrid memory approach wins. Build agents that can access both past interactions and current state through a layered LangChain memory module guide architecture.
Quantifying Token Drain

Formula: Token × Price/1K × Calls/Day
To measure memory cost, use the token calculator formula:
Daily Token Cost = (Avg tokens/call) × ($/1K tokens) × (# calls/day)
Track token-per-successful-action (TPSA) as your primary KPI. It aligns memory use with real business outcomes.
Case Snapshot: Token Drain in E-Commerce Agent
An e-commerce assistant using 2K tokens/call across 4K calls/day racks up $384 daily. That’s $11.5K/month just for context persistence. The stateless design here becomes a liability in stateful vs stateless architectures for AI applications.
Three Design Patterns to Slash Spend
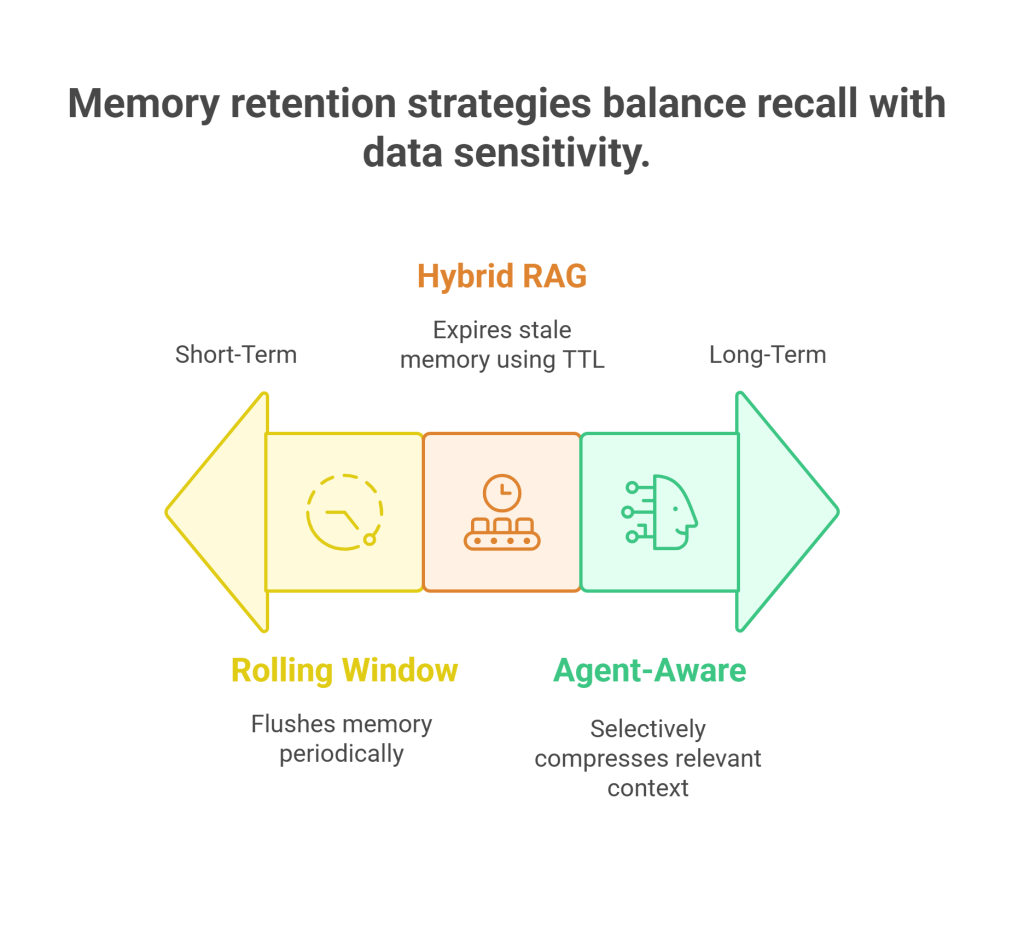
Rolling Window + Episodic Flush
Use short-lived rolling context with periodic memory flushes. Helps reduce redundant memory recall and keeps workflows stateless when the state isn’t needed.
memory = ConversationBufferMemory(ttl_seconds=600)
Hybrid RAG Memory with TTL Index
Blend summarization and vector recall with TTL policies to expire stale memory. Ensures that long-term context doesn’t overflow or expose sensitive data in every interaction.
Agent-Aware Compression (LoRA Summarizer)
LoRA fine-tuned summarizers can selectively compress context engineering. These stateful AI agents can retain only what matters. Karpathy said it best: “Agents that can actually learn need to forget selectively.”
Interactive Cost Calculator Walkthrough

Input Your Model: GPT-4o vs Claude 3 Sonnet
This calculator lets teams plug in their current model (GPT-4o, Claude 3, or custom fine-tunes), define average tokens per call, and set expected daily volume. It reveals where your budget is bleeding before your CFO does.
The interface includes drop-down menus for model types, sliders for context length, and real-time estimates for cost-per-agent based on your actual use case. You can toggle between stateless and stateful agent designs to see the financial impact immediately.
Output Visualization: See Your Token Bleed
Visual graphs show cost deltas side-by-side: GPT-4o running with a 6K context window versus Claude memory using a 3K summarization setup. The difference? A potential reduction in context window cost with no drop in performance.
These insights can be shared directly with FinOps or product leadership. It’s a powerful way to justify memory redesigns and advocate for stateful agents with Context-Engineering ROI.
KPI Framework for Stateful Agent Ops
Memory-Hit Ratio (MHR)
The memory-hit ratio tracks how often the agent retrieves useful context from memory. A well-configured stateful agent should reach at least a 60% MHR within the first month of deployment. Lower ratios mean you’re storing memory that’s never being used, pure token-cost model with zero return.
Token-per-Successful-Action (TPSA)
TPSA measures the number of tokens spent to complete a successful user action. The lower the TPSA, the more efficient your agent is. For AI systems in production, a TPSA under 1,500 is typically the green zone. If your TPSA is pushing 2,500 or more, it’s time to review your memory policies.
Hallucination Rate vs. Window Size
Larger window sizes often correlate with higher hallucination rates. That’s because older, irrelevant tokens dilute prompt clarity. Studies show that hallucination rates spike past the 12K-token threshold. By monitoring this KPI, teams can set soft limits for context windows and trigger summarization when needed.
90-Day Implementation Roadmap
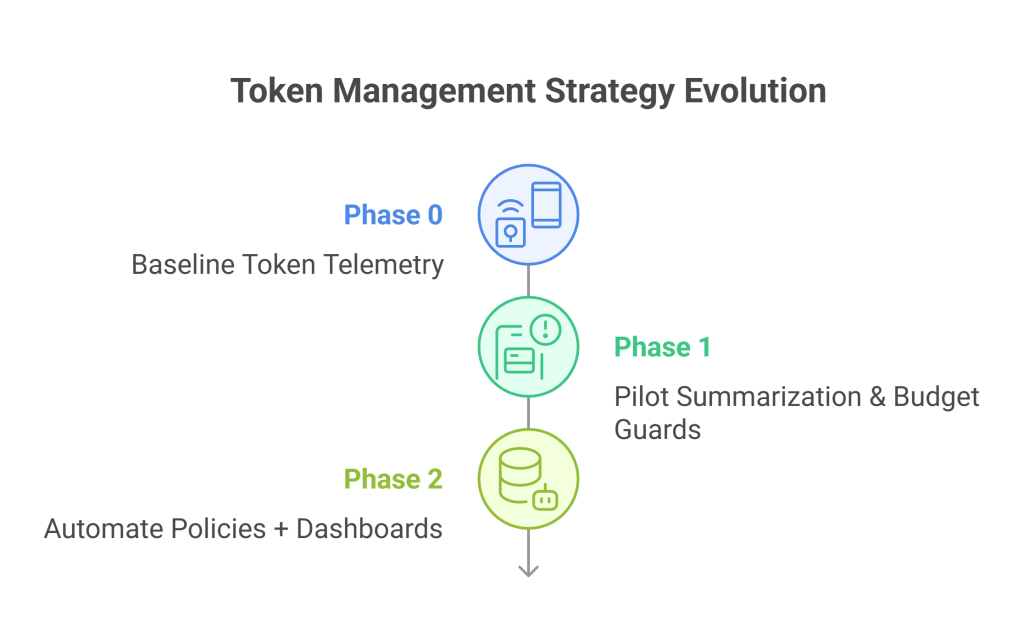
Phase 0: Baseline Token Telemetry
- Instrument token usage via Grafana or Datadog
- Track model calls per agent
- Monitor stateless vs stateful agent performance
Phase 1: Pilot Summarization & Budget Guards
- Choose two high-traffic agents
- Implement summarization windows
- Set token budget alerts
Phase 2: Automate Policies + Dashboards
- TTL-based memory storage
- KPI dashboards tracking TPSA, MHR
- Token observability loop embedded in the dev workflow
Risk & Compliance Lens

Prompt-Injection Safe Memory Stores
Storing prompts or message histories without filtration is risky for stateful and stateless designs. Prompt injection vulnerabilities can lead to logic hijacks or accidental data leaks. Mozilla Securing LLM Logs white-paper, Stateful agents should use validated memory stores that filter inputs through an allowlist or pattern match before persistence. Avoid free-form user memory capture at all costs. Injecting memory into an agent’s context should be a privilege, not a default.
PII Redaction in Long-Term Logs
If your agents retain long-term memory, they will eventually touch sensitive data. That means compliance obligations kick in. Design memory storage with persistent memory in mind.
- Regex-based redaction for emails, phone numbers, and identifiers
- Opt-in memory flags for storing any user-related content
- Scheduled deletion policies to purge stale long-term logs
This builds audit-ready, compliance-safe AI workflows without blocking development speed.
Executive FAQ: Objection Handling for Cross-Teams
Will memory slow things down?
Not if done right, stateless agents with token sprawl are slower due to bloat.
Why not build our own summarizer?
Building your own summarizer might seem cheap upfront, but maintaining it and integrating it into your token calculator workflows adds engineering overhead. By contrast, using an AWS Cost Intelligence Dashboard template gives you built-in cost-tracking and optimization insights with minimal setup
Is this vendor lock-in?
No, this isn’t vendor lock-in, because you can design your agentic system to be LLM‑agnostic and switch models easily. The Episodic Memory in LLM Agents framework supports independent memory layers that stay usable across different backends
Conclusion
Stateful agents aren’t a luxury anymore; they’re a cost-saving, performance-boosting necessity. The days of blindly expanding context windows are over. With real telemetry, smart memory design, and governance baked into your workflows, you can build LLM-powered systems that are cheaper, faster, and far more accurate.
The future of AI isn’t just about output, it’s about memory. Let your agents evolve, retain what matters, and continuously improve. Because agents learn and remember.